基本概念
哈希表(HashTable)是一个重要的底层数据结构, 无序关联容器包括unordered_set, unordered_map内部都是基于哈希表实现。
- 哈希表是一种通过哈希函数将键映射到索引的数据结构,存储在内存空间中。
- 哈希函数负责将任意大小的输入映射到固定大小的输出,即哈希值。这个哈希值用作在数组中存储键值对的索引。
用途
那么哈希表能解决什么问题呢,一般哈希表都是用来快速判断一个元素是否出现集合里。
例如要查询一个名字是否在这所学校里。
要枚举的话时间复杂度是O(n),但如果使用哈希表的话, 只需要O(1)就可以做到。
我们只需要初始化把这所学校里学生的名字都存在哈希表里,在查询的时候通过索引直接就可以知道这位同学在不在这所学校里了。
将学生姓名映射到哈希表上就涉及到了hash function ,也就是哈希函数。
冲突解决
由于哈希函数的映射不是一对一的,可能会出现两个不同的键映射到相同的索引,即冲突。可以使用链地址法解决冲突,即在哈希表的每个槽中维护一个链表,将哈希值相同的元素存储在同一个槽中的链表中。
哈希表的扩容与rehashing
为了避免哈希表中链表过长导致性能下降,会在需要时进行扩容。
扩容过程涉及到重新计算所有元素的哈希值,并将它们分布到新的更大的哈希表中。这一过程称为rehashing。
思路
class HashNode{
public:
Key key;
Value value;
......;
}
using Bucket = std::list<HashNode>;
std::vector<Bucket> buckets; // 定义由多个槽连续组成的数组
在上述代码中,我们会定义以下几个变量名,它们的意义如下图所示:
- HashNode表示链表的一个节点
- Bucket表示一个桶,桶里面装的是链表,实际上因为冲突,桶里面的链表往往只有一个节点
- buckets表示系统开辟一块块Bucket大小的连续内存空间

然后我们模拟哈希表的插入流程,如下图的①②③④⑤:
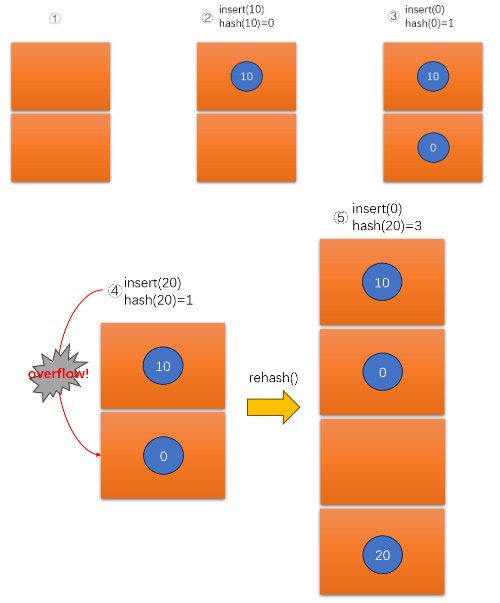
- 首先我们定义
std::vector<Bucket> buckets,它是两块Bucket大小的连续内存空间,也就是两个桶。但桶里面是没有东西的 - 当向哈希表中插入10时(
insert(10)),首先会通过哈希函数计算出索引(hash(10)=0),那么就在第一个桶(Bucket)中放入节点⑩ - 当向哈希表中插入0时(
insert(0)),首先会通过哈希函数计算出索引(hash(0)=1),那么就在第二个桶(Bucket)中放入节点⓪ - 当向哈希表中插入20时(
insert(20)),首先会通过哈希函数计算出索引(hash(20)=1),出现两个不同的键映射到相同的索引,即冲突。可以使用链地址法解决冲突,即在哈希表的每个槽中维护一个链表。 - 由于桶的数量不够了,需要扩容哈希表(
rehash),扩容后的容量翻倍。通过哈希函数计算出索引(hash(20)=3),那么就在第四个桶(Bucket)中放入节点⑳
代码实现
HashTable.h
#include <algorithm>
#include <cstddef>
#include <functional>
#include <iostream>
#include <list>
#include <utility>
#include <vector>
#include <sstream>
#include <string>
namespace mystl{
template <typename Key, typename Value, typename Hash = std::hash<Key>>
class HashTable{
// 链表中要维护的jie'd
class HashNode{
public:
Key key;
Value value;
// 从Key构造节点,Value使用默认构造
explicit HashNode(const Key &key): key(key), value(){}
// 从Key和Value构造节点
HashNode(const Key &key, const Value &value):key(key), value(value){}
// 比较运算符重载,比较key
bool operator==(const HashNode &other) const { return key == other.key;}
bool operator!=(const HashNode &other) const { return key != other.key; }
bool operator<(const HashNode &other) const { return key < other.key; }
bool operator>(const HashNode &other) const { return key > other.key; }
bool operator==(const Key &key_) const { return key == key_; }
void print() const
{
std::cout<<"(" << key <<","<< value<<")" << " ";
}
};
private:
// 定义表中一个桶(Bucket),桶里面装的是一个个HashNode节点组成的链表
using Bucket = std::list<HashNode>;
std::vector<Bucket> buckets; // 定义由多个槽连续组成的数组
std::hash<Key> hashFunction; // 定义一个哈希函数
size_t tableSize; // 哈希表的最大容量
size_t numElements; // 哈希表中当前元素的数量
float maxLoadFactor = 0.75; // 默认的最大负载因子
// 哈希函数计算key的值,取模防止溢出,作为哈希表的索引
size_t hash(const Key &key) const { return hashFunction(key)%tableSize; }
// 当元素数量大于最大容量时,增加桶的数量并重新分配所有键
void rehash(size_t newSize)
{
std::vector<Bucket> newBuckets(newSize);// 创建一个新的桶数组,大小为newsize
for(Bucket &bucket : buckets) // 遍历原来的桶数组buckets,轮流取出其中的一个桶(bucket)
{
// 链表遍历
for(HashNode &hashNode : bucket) // 遍历原来的桶bucket,它是一个链表,轮流取出其中的一个节点(hashNode)
{
// 新的索引与原来的索引相同
size_t newIndex = hashFunction(hashNode.key)%newSize;// 计算新的索引
newBuckets[newIndex].push_back(hashNode);
}
}
// 移动语义
buckets = std::move(newBuckets);
tableSize = newSize;
}
public:
// 哈希表构造函数初始化, 注意:typename Hash = std::hash<Key>
/*
std::hash<Key>() 创建了一个临时的 std::hash<Key> 对象。
因为 std::hash<Key> 有一个默认的构造函数(无参数的构造函数),所以可以直接这样调用它来创建一个临时对象。
这个临时对象被用来初始化之后,就销毁
*/
HashTable(size_t size = 0, const std::hash<Key> &hashFunc = Hash()):buckets(size),hashFunction(hashFunc),tableSize(size),numElements(0){}
// 将键值对插入哈希表中
void insert(const Key &key, const Value &value)
{
if((numElements + 1) > maxLoadFactor * tableSize) // 乘以一个负载因子,保证哈希表预留的空间足够多,计算出的索引不容易发生冲突,减少拷贝次数
{
if(tableSize == 0)
tableSize = 1;
rehash(tableSize * 2);
}
size_t index = hash(key); // 计算索引
Bucket &bucket = buckets[index]; // 找出该索引对应的桶
if(std::find(bucket.begin(),bucket.end(),key) == bucket.end()) // 如果桶中没有链表,则在该桶中插入该链表;如果有,则直接跳过
{
bucket.push_back(HashNode(key, value));
numElements++;
}
}
void insertKey(const Key &key) { insert(key, Value{}); } // 值为空的情况
void erase(const Key &key)
{
size_t index = hash(key); // 计算索引
auto &bucket = buckets[index]; // 找出该索引对应的桶
auto it = std::find(bucket.begin(), bucket.end(), key);
if(it != bucket.end())
{
// 找到该链表,删除它
bucket.erase(it);
numElements--;
}
}
Value* find(const Key &key)
{
size_t index = hash(key);
auto &bucket = buckets[index];
auto ans = std::find(bucket.begin(), bucket.end(), key);
if(ans != bucket.end())
{
return &ans->value; // 返回结点value所在的地址
}
return nullptr;
}
size_t size() const { return numElements; }
void print() const
{
for(size_t i = 0; i < buckets.size(); i++)
{
for(const HashNode &element : buckets[i])
{
element.print(); // 调用HashNode类的成员函数print
}
}
std::cout << std::endl;
}
void clear()
{
this->buckets.clear();
this->numElements = 0;
this->tableSize = 0;
}
};
}
test.cpp
#include "vector.h"
#include "list.h"
#include "deque.h"
#include "HashTable.h"
void HashTableTest()
{
mystl::HashTable<int, int> hashTable;
for(int i = 0;i<5;i++)
{
hashTable.insert(i, i*2);
hashTable.print();
}
hashTable.print();
int* t = hashTable.find(3);
std::cout << *t << std::endl;
hashTable.erase(3);
hashTable.print();
hashTable.clear();
hashTable.print();
}
int main()
{
HashTableTest();
system("pause");
return 0;
}
代码详解
代码的注释已经很详细啦,所以就不一个个讲了(其实我就是懒~😜)
主要讲解一下移动语义这个知识点
移动语义
参考这篇博客,写得非常好🙂:[c++11]我理解的右值引用、移动语义和完美转发 - 简书 (jianshu.com)
std::move()可以让一个左值进行右值引用,这样在给其它变量赋值的时候,就不用额外拷贝一次临时变量。
那什么叫左、右值?什么叫左值引用、右值引用呢?
左值右值
C++中所有的值都必然属于左值、右值二者之一。左值是指表达式结束后依然存在的持久化对象,右值是指表达式结束时就不再存在的临时对象。所有的有名字的变量或者对象都是左值,而右值则没有名字。
- 左值:
int a = 10 - 右值:如
1+2产生的临时变量,2,'c',true,"hello"等
很难得到左值和右值的真正定义,但是有一个可以区分左值和右值的便捷方法:看能不能对表达式取地址,如果能,则为左值,否则为右值。
左值引用,右值引用
左值引用就是我们经常说的引用,也就是给变量取别名,要注意不能给右值取左值引用,因为当我们修改b的值时,就是修改1的值,但由于1没有内存空间,修改不了,所以不符合左值引用的要求
int a = 10;
int& refA = a; // refA是a的别名, 修改refA就是修改a, a是左值,左移是左值引用
int& b = 1; // !编译错误! 1是右值,不能够使用左值引用
c++11中的右值引用使用的符号是&&,它允许我们对右值进行引用,如:
int&& a = 1; //实质上就是将不具名(匿名)变量取了个别名
int b = 1;
int && c = b; //编译错误! 不能将一个左值复制给一个右值引用
class A {
public:
int a;
};
A getTemp()
{
return A();
}
A && a = getTemp(); //getTemp()的返回值是右值(临时变量)
同样我们也要注意不能给左值取右值引用
在上面代码中,getTemp()返回的右值本来在表达式语句结束后,其生命也就该终结了(因为是临时变量),而通过右值引用,该右值又重获新生,其生命期将与右值引用类型变量a的生命期一样,只要a还活着,该右值临时变量将会一直存活下去。实际上就是给那个临时变量取了个名字。
注意:这里a的类型是右值引用类型(int &&),但是如果从左值和右值的角度区分它,它实际上是个左值。因为可以对它取地址,而且它还有名字,是一个已经命名的右值。因此,编译器会认为a是个左值。
万能引用
那有没有一种引用,既可以左值引用,也可以右值引用呢?
有,它就是常量引用。常量左值引用是个奇葩,它可以算是一个“万能”的引用类型,它可以绑定非常量左值、常量左值、右值,而且在绑定右值的时候,常量左值引用还可以像右值引用一样将右值的生命期延长,缺点是,只能读不能改。
const int & a = 1; //常量左值引用绑定 右值, 不会报错
class A {
public:
int a;
};
A getTemp()
{
return A();
}
const A & a = getTemp(); //不会报错 而 A& a 会报错
总结一下:
- 左值引用, 使用
T&, 只能绑定左值- 右值引用, 使用
T&&, 只能绑定右值- 常量左值, 使用
const T&, 既可以绑定左值又可以绑定右值- 已命名的右值引用,编译器会认为是个左值
移动语义、拷贝
#include <iostream>
#include <cstring>
#include <vector>
using namespace std;
class MyString
{
public:
static size_t CCtor; //统计调用拷贝构造函数的次数
// static size_t CCtor; //统计调用拷贝构造函数的次数
public:
// 构造函数
MyString(const char* cstr=0){
if (cstr) {
m_data = new char[strlen(cstr)+1];
strcpy(m_data, cstr);
}
else {
m_data = new char[1];
*m_data = '\0';
}
}
// 拷贝构造函数
MyString(const MyString& str) {
CCtor ++;
m_data = new char[ strlen(str.m_data) + 1 ];
strcpy(m_data, str.m_data);
}
// 拷贝赋值函数 =号重载
MyString& operator=(const MyString& str){
if (this == &str) // 避免自我赋值!!
return *this;
delete[] m_data;
m_data = new char[ strlen(str.m_data) + 1 ];
strcpy(m_data, str.m_data);
return *this;
}
~MyString() {
delete[] m_data;
}
char* get_c_str() const { return m_data; }
private:
char* m_data;
};
size_t MyString::CCtor = 0;
int main()
{
vector<MyString> vecStr;
vecStr.reserve(1000); //先分配好1000个空间,不这么做,调用的次数可能远大于1000
for(int i=0;i<1000;i++){
vecStr.push_back(MyString("hello"));
}
cout << MyString::CCtor << endl;
}
在这段代码中,vecStr.push_back(MyString("hello"))工作流程如图:它会依次调用MyString(const char* cstr=0)创建一个右值、在插入的时候通过MyString(const MyString& str)`拷贝一份Mystring变量
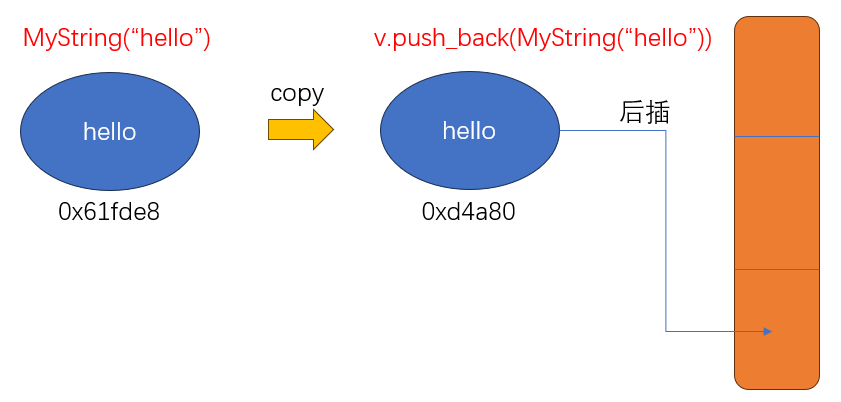
如果MyString("hello")构造出来的字符串(比如MyString("hello abcdefghigklmnopqrstuvwsyzasd……………………"))本来就很长,构造一遍就很耗时了,最后却还要拷贝一遍,而MyString("hello")只是临时对象,拷贝完就没什么用了,这就造成了没有意义的资源申请和释放操作。
那能不能去掉这个copy(黄色箭头)拷贝过程,直接将这个右值插入呢?而C++11新增加的移动语义就能够做到这一点。
#include <iostream>
#include <cstring>
#include <vector>
using namespace std;
class MyString
{
public:
static size_t CCtor; //统计调用拷贝构造函数的次数
static size_t MCtor; //统计调用移动构造函数的次数
static size_t CAsgn; //统计调用拷贝赋值函数的次数
static size_t MAsgn; //统计调用移动赋值函数的次数
public:
// 构造函数
MyString(const char* cstr=0){
if (cstr) {
m_data = new char[strlen(cstr)+1];
strcpy(m_data, cstr);
}
else {
m_data = new char[1];
*m_data = '\0';
}
}
// 拷贝构造函数
MyString(const MyString& str) {
CCtor ++;
m_data = new char[ strlen(str.m_data) + 1 ];
strcpy(m_data, str.m_data);
}
// 移动构造函数
MyString(MyString&& str) noexcept
:m_data(str.m_data) {
MCtor ++;
str.m_data = nullptr; //不再指向之前的资源了
}
// 拷贝赋值函数 =号重载
MyString& operator=(const MyString& str){
CAsgn ++;
if (this == &str) // 避免自我赋值!!
return *this;
delete[] m_data;
m_data = new char[ strlen(str.m_data) + 1 ];
strcpy(m_data, str.m_data);
return *this;
}
// 移动赋值函数 =号重载
MyString& operator=(MyString&& str) noexcept{
MAsgn ++;
if (this == &str) // 避免自我赋值!!
return *this;
delete[] m_data;
m_data = str.m_data;
str.m_data = nullptr; //不再指向之前的资源了
return *this;
}
~MyString() {
delete[] m_data;
}
char* get_c_str() const { return m_data; }
private:
char* m_data;
};
size_t MyString::CCtor = 0;
size_t MyString::MCtor = 0;
size_t MyString::CAsgn = 0;
size_t MyString::MAsgn = 0;
int main()
{
vector<MyString> vecStr;
vecStr.reserve(1000); //先分配好1000个空间
for(int i=0;i<1000;i++){
vecStr.push_back(MyString("hello"));
}
cout << "CCtor = " << MyString::CCtor << endl;
cout << "MCtor = " << MyString::MCtor << endl;
cout << "CAsgn = " << MyString::CAsgn << endl;
cout << "MAsgn = " << MyString::MAsgn << endl;
}
/* 结果
CCtor = 0
MCtor = 1000
CAsgn = 0
MAsgn = 0
*/
在上述代码中,我们新增了一个移动拷贝构造:
// 移动构造函数
MyString(MyString&& str) noexcept:m_data(str.m_data) {
MCtor ++;
str.m_data = nullptr; //不再指向之前的资源了
}
移动构造函数与拷贝构造函数的区别是,拷贝构造的参数是const MyString& str,是常量左值引用,而移动构造的参数MyString&& str,是右值引用,而MyString("hello")是个临时对象,是个右值,优先进入移动构造函数而不是拷贝构造函数。而移动构造函数与拷贝构造不同,它并不是重新分配一块新的空间,将要拷贝的对象复制过来,而是"偷"了过来,将自己的指针指向别人的资源,然后将别人的指针修改为nullptr,这一步很重要,如果不将别人的指针修改为空,那么临时对象析构的时候就会释放掉这个资源,"偷"也白偷了。下面这张图可以解释copy和move的区别。
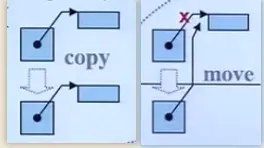
通过这种方法,我们就可以让一个右值,不用进行拷贝,直接移动到该去的地方
对于一个左值,肯定是调用拷贝构造函数了。比如上面我们将main函数修改一下:
int main()
{
vector<MyString> vecStr;
vecStr.reserve(1000); //先分配好1000个空间
for(int i=0;i<1000;i++){
MyString s = MyString("hello");
vecStr.push_back(s);
}
cout << "CCtor = " << MyString::CCtor << endl;
cout << "MCtor = " << MyString::MCtor << endl;
cout << "CAsgn = " << MyString::CAsgn << endl;
cout << "MAsgn = " << MyString::MAsgn << endl;
}
可以看出这个左值,进入到了拷贝构造里面了,而不是移动构造中!
但是有些左值是局部变量,生命周期也很短,能不能也移动而不是拷贝呢?C++11为了解决这个问题,提供了std::move()方法来将左值转换为右值,从而方便应用移动语义。
我觉得它其实就是告诉编译器,虽然我是一个左值,但是不要对我用拷贝构造函数,而是用移动构造函数吧。
现在我们再将main函数修改一下:
int main()
{
vector<MyString> vecStr;
vecStr.reserve(1000); //先分配好1000个空间
for(int i=0;i<1000;i++){
MyString s = MyString("hello");
vecStr.push_back(std::move(s));
}
cout << "CCtor = " << MyString::CCtor << endl;
cout << "MCtor = " << MyString::MCtor << endl;
cout << "CAsgn = " << MyString::CAsgn << endl;
cout << "MAsgn = " << MyString::MAsgn << endl;
}
可以看出这个左值,进入到了移动构造里面了!
所以:std::move()可以让一个左值进行右值引用,这样在给其它变量赋值的时候,就不用额外拷贝一次临时变量。
C11中元素遍历Bucket &bucket:buckets
等同于
for(int i =0;i<buckets.size();i++)
{
bucket = buckets[i];
…………
}